
Why Shadow AI Is Invisible to Legacy Scanners
"Shadow AI" cannot be reliably uncovered using legacy keyword scanners. And without a full view into deployed AI assets, companies are exposed to both intentional external threats and unintended internal drift in security that might be exploited externally. Yet building an accurate inventory of AI models and agents requires deep semantic analysis of the code. This article describes AQtive Guard’s AI discovery strategy, the foundational challenges stemming from the complexity of modern software, and how we optimized the tradeoff between precision and speed.
As AI agents, Large Language Models (LLMs), and Model Context Protocol (MCP) servers are being integrated into modern software, tracking their usage is a critical security mandate. For an AI Security Posture Management (AI-SPM) solution, building an accurate inventory of these assets is an essential first step, especially given the possibility of Shadow AI. It is also preferred to have access to the inventory before the software is executed, i.e. statically by inspecting the source code (as opposed to dynamically while executing the software), hence the use of static analyzers.
But here is the foundational challenge: discovering AI assets in a repository isn't a simple text search. Many pattern-based static analyzers would either report on every instance of importing AI libraries, introducing false positive findings, or they would over-correct and miss shadow AI that isn’t matching the pattern. AI dependencies are not always declared in a clean, easily parsable manifest. They are embedded within the logic of the code itself, their discovery is equivalent to understanding the possible behaviors of the code.
To solve this, we are reformulating the problem of AI discovery into a sequence of questions about code semantics. By treating source code as a queryable graph database and leveraging advanced static analysis, we are building a universal engine capable of deeply understanding the observable behavior of a software system.
The Limits of Syntax-Based Analysis
When trying to locate where an application calls an external LLM, the initial instinct is often to rely on lexical searches or regular expressions: looking for strings like "gpt-4" or "claude", in files that also contain import genai for example.
However, syntax only tells you what the code looks like, not how it behaves. In a dynamic codebase, data is passed through variables, returned by helper functions, and embedded in complex data structures.
Consider three different ways (out of many other possibilities) a developer might specify a model:
- Directly: Passing the model name as a hardcoded string literal into an API call.
- Indirectly: Assigning the model name to a variable at the top of a file, then passing that variable into a function later on.
- Dynamically: Using a factory function that determines and returns the model name based on the execution context.
A simple syntactic scanner will likely catch the first case, miss the second if the variable name is obscure, and entirely fail on the third, because the model name is not present as a string literal anywhere near the call site. To accurately identify AI assets, an analysis engine must move beyond the syntax and understand the flow of data.
How Static Data Flow Analysis Finds Hidden AI Models
To bridge the gap between how code is written (syntax) and how it behaves when executed (semantics), our underlying engine relies heavily on Data Flow Analysis and Symbol Resolution. These two concepts have long been understood by the research community and are a necessary part of every compiler. Data flow analysis tracks content of variables from their definitions (assignments) to their uses (for example as call arguments). Symbol resolution identifies the unique name of every symbol by interpreting the scoping rules of programming languages.
Unlike a compiler, a modern code scanner needs to be easily deployable on arbitrary code repositories, often without full understanding of the particular build system used by the repository. As a consequence, the scanner does not see the parts of the compilation unit that are imported dynamically by the build system: it has to work with an incomplete view of the code. To use data flow analysis and symbol resolution efficiently on an incomplete code is, however, non-trivial. For a compiler, symbol resolution is essential and needs to be perfectly precise, so it needs to see the whole compilation unit, including all imported symbols. Our analysis needs to operate even in cases where the view of known symbols is incomplete.
On the other hand, data flow analysis is an optimization feature in compilers, it needs to run fast and do the best effort of identifying optimization potential, but is expected to be highly approximating. Whereas the use case for us is quite different: we need very high precision when analyzing data flow to identify the models (agents, MCPs) as accurately as possible.
Flow Sensitivity, Context Sensitivity, and Field Sensitivity Explained
To that end (and unlike standard compiler data flows) our analysis respects execution order (flow sensitive), call stack (context sensitive), and per-field object updates (field sensitive) accurately.
Instead of looking at isolated lines of text, the engine parses the code and creates an abstraction of the program's potential execution states. It traces the lifecycle of a variable from its allocation site (where it is assigned to) to its sink (where it is used).
The diagram 1 above depicts the composition of the analysis engine. The analysis internally implements symbol resolution and data flow analysis as separate components together with the parser wrapper and syntactic analysis. Each step is internally executed in parallel for every code file, with synchronization points that communicate interfile data on-demand.
When our engine looks for an LLM inference call, it doesn't just look at the arguments directly passed to it. It traces the execution paths backward, resolving variables and function returns across multiple files, to accurately determine the underlying value. It allows the analyzer to confidently state, "Regardless of how this variable was passed around, at the moment this API is called, its value represents this specific AI model."

A Step-by-Step Example: Tracing a Claude Model Through Python Code
The short example above already demonstrates some of the complexities of building AI inventory:
- we start by identifying anthropic.Anthropic.messages.create as the relevant LLM call
- next we need to extract the runtime value of its model argument
- the argument is the return value of the call to get_name with receiver model_name
- model_name’s runtime value is either ModelConfig(“claude-haiku-4”) or ModelConfig(“claude-opus-4”) but in either case the type is ModelConfig and using interfile symbol resolution we can resolve get_name to its definition in file1.py
- now we need to find the last assignment to self.name that happened before calling get_name
- for that we reconstruct the execution backwards starting at get_name()
- the execution branches when assigning to model_name so we explore both pasts (our analysis is flow sensitive) but let’s only continue the exposition via the Haiku route
- while interpreting the constructor call we internally recognize that self from file1 represents model_name from file2
- when analyzing self.name = name we know that the runtime value of the left-hand side name is ”claude-haiku-4” (since our analysis is context sensitive) and that self has runtime value ModelConfig(“claude-haiku-4”)
- finally when we see return self.name we know that name is a field of an object updated before and we know the update (due to field sensitivity) and can thus conclude that the model used for LLM inference was Haiku 4 (and also Opus 4, which we find repeating steps 8--10 for the other execution branch)
As we can see, even a perfectly simple piece of code may require advanced analyses techniques to produce accurate inventory.
Building a Universal Query Engine for Code Semantics
Writing custom analysis logic for every new AI framework or cryptographic library is unsustainable. To scale our security posture management, we are reducing the problem by solving a more fundamental one: providing a database-like interface to arbitrary codebase.
Rather than hardcoding extraction rules into the core parser, we decouple the extraction logic from the analysis engine. The engine’s sole job is to ingest a repository, perform the heavy computational lifting of interfile data flow analysis, and construct a highly optimized, queryable view of the program.
Once the code is loaded into this abstraction, security researchers can interact with it using a standardized querying layer. They can ask complex semantic questions without needing to understand compiler theory or the specific programming language the target application is written in.
A query simply states the desired outcome: for example, "Identify all call-sites that invoke this specific AI agent library, and return the underlying string values of its first argument." The engine handles the complex traversal and state approximation internally.
Declarative vs. Imperative Queries: What Security Researchers Need
Declaratively, we can “define” the inventory as a collection of relations, e.g.

Imperatively, we can do exactly the same but using Python as a querying language:

How AQtive Guard Unifies AI-SPM and Cryptographic Posture Management
AQtive Guard by SandboxAQ (AQG) now contains our solution to AI-SPM, exposing all AI assets found in customers' codebases. Together with the pre-existing cryptographic inventory, AQG provides a 360-view into the security posture of complex IT environments.
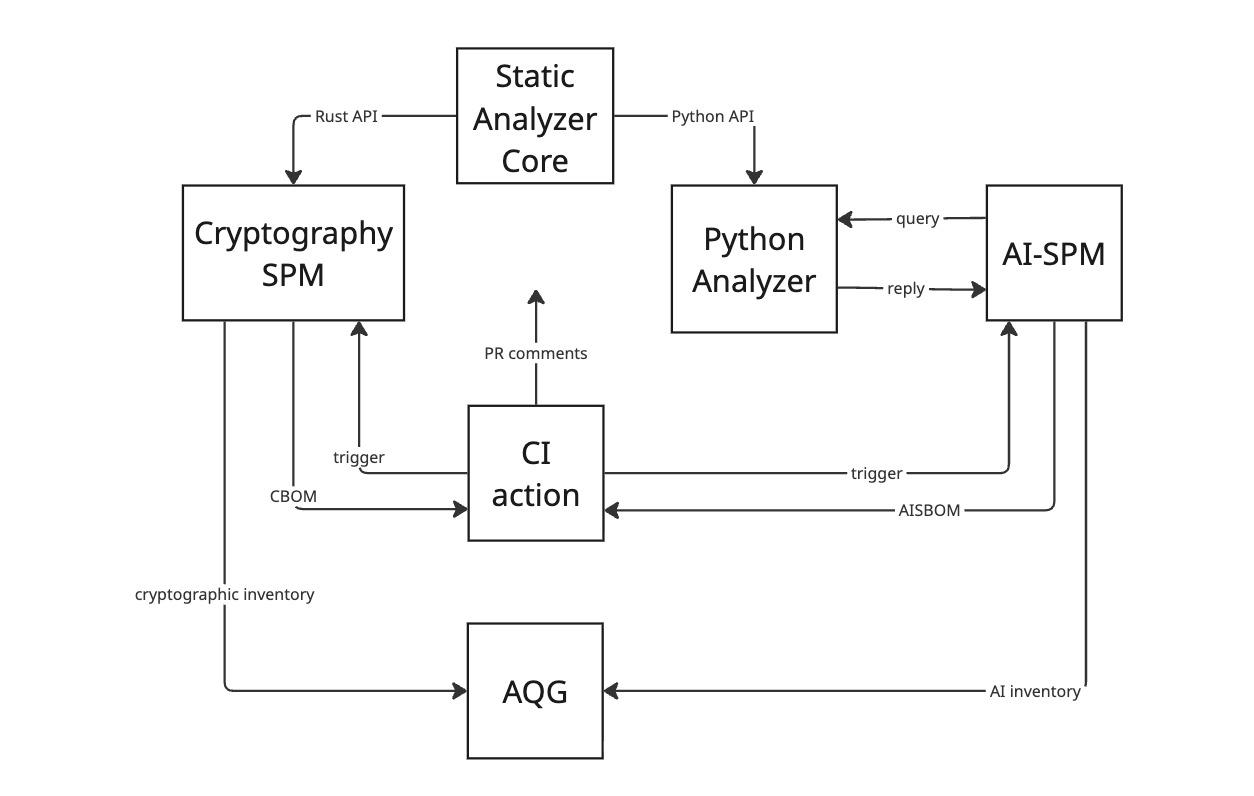
From AISBOM to AI Inventory: The AQG Workflow

The diagram 2 above shows how the analysis fits the AQG workflow. The scan itself is triggered by GitHub/GitLab CI action. For the AI-SPM path, we then query the Python interface of the analyzer with rule-based queries that define the AI assets to populate the inventory. Once complete, the inventory is sent to AQG for further enrichment, compliance reporting, issues identification, and other functions.
The fundamentals of tracking data flow are domain-agnostic. The logic required to trace a cryptographic key through an application is fundamentally the same as the logic required to trace an LLM prompt or an MCP server address.
Historically, the industry has built siloed scanners for different domains: one for cryptography, one for secrets, one for AI. By building a single, highly optimized foundational query engine, we are unifying these efforts. And since problems from each domain are reduced to a shared set of queries, improvements in one area have a positive impact across the board.
This architectural shift allows us to:
- Reduce Overhead: Customers run a single, highly performant scanner across their repositories.
- Improve Accuracy: By leveraging deep semantic analysis rather than shallow syntax checks, we drastically reduce false positives and uncover hidden assets.
- Accelerate Rule Creation: Security researchers can deploy new extraction rules purely as queries, without altering the underlying scanning infrastructure.
By treating code not as text, but as a complex system of interconnected data flows, we are building an AI-SPM platform capable of securing the next generation of software. In our internal benchmarks we already accurately identify 85% of language models used in code (in the top 1000 public repositories on GitHub), which enables us to provide a comprehensive view into the AI assets across customers' codebases.



